
Час читання: 2 хв.
OpenAI розробила новий еталонний тест HealthBench для оцінки медичних знань мовних моделей. У його створенні взяли участь 262 лікарі з 60 країн, які розробили 5000 реалістичних сценаріїв за 26 медичними темами 49 мовами.
Тест охоплює сім галузей медицини й оцінює ШІ за п’ятьма критеріями, включно з якістю комунікації, точністю і розумінням контексту, використовуючи 48 000 медично обґрунтованих метрик. Останні моделі GPT-4.1 і o3 продемонстрували результати, що перевершують відповіді лікарів у всіх п’яти оціночних категоріях.
Реклама
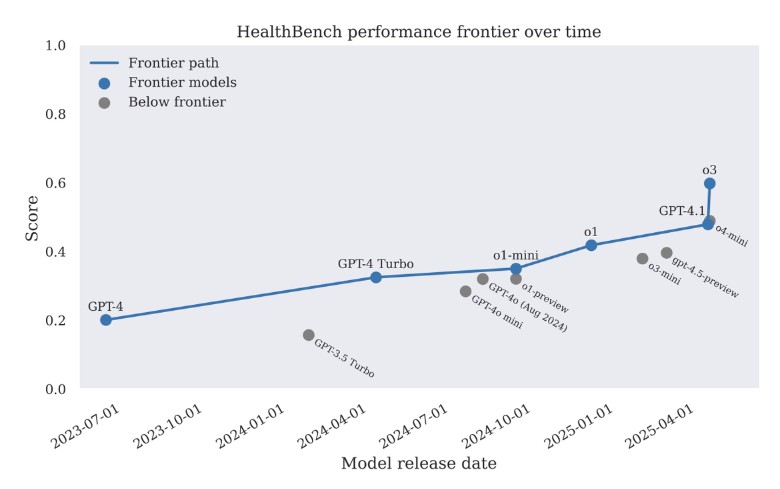
Якщо у вересні 2024 року лікарі могли покращувати відповіді старих моделей, то до квітня 2025-го нові алгоритми стали автономно ефективнішими за фахівців. Модель o3 набрала 0,60 бала проти 0,32 у GPT-4o лише півроку тому, залишивши позаду конкурентів на кшталт Grok 3 і Gemini 2.5.
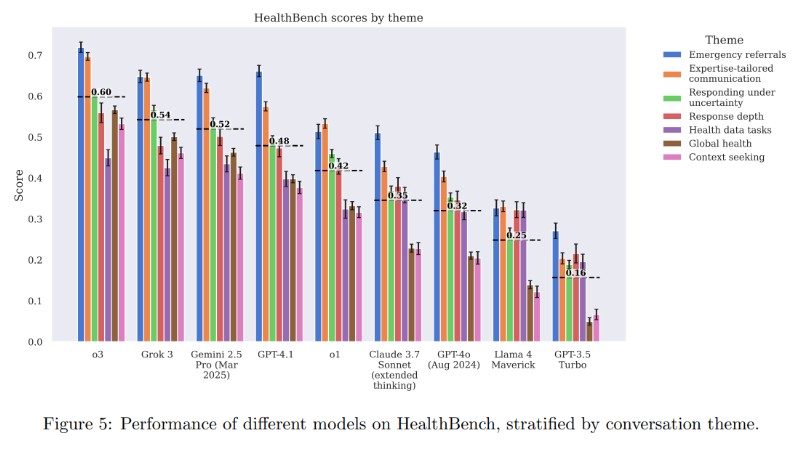
Тест оцінює лише специфічний аспект комунікації, а не реальну клінічну практику. Але GPT-4.1 скоротив кількість помилок у складних випадках, а більш компактна модель GPT-4.1 nano виявилася в 25 разів економічнішою за попередників. Усі матеріали тесту опубліковані у відкритому доступі на GitHub.